Since I needed a simple report on the elements used in a set of XML files, along with some additional information like how often used, attributes, children, and if an element contained character data yes or no, I decided to start with xmlelements.pl as given in Finding the number of unique XML elements and extend this Perl program with the required additional functionality.
The program executes in a way very similar to xmlelements.pl. For the extra functionality however, a handler for character data and a handler for encountering the end of an element is required as well.
Each time a new element is encountered it's pushed onto an element stack. The end handler is required to pop this element off the stack when its end has been encountered.
The start handler is extended with code to count attribute occurrences. Also if the current element is a child of another element, the count that the parent keeps for this child element is increased by one. The element stack is used to access the parent. The index of -1 belongs to the last element of the stack if there are elements on this stack. Finally the current element is pushed on top of the stack.
The character data handler just sets a flag of the current element on the stack if any to one in order to signal that this element contains character data.
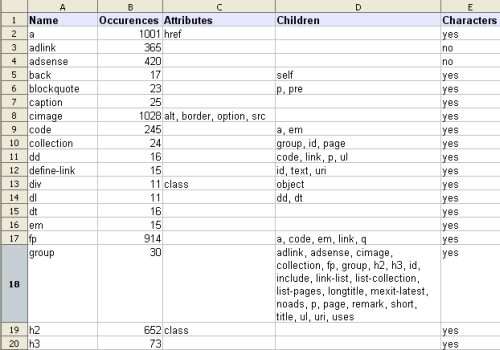
Finally, the program prints out a tab separated overview, preceded by a header line with a short description for each column. The output can be redirected to a file for example. When this file has the extension csv (what's in a name), it can be opened in the Calc program that comes with OpenOffice by double clicking the result file on Windows XP.
#!/usr/bin/perl
#
# xmlelements-report.pl
#
# © Copyright, 2006 by John Bokma, http://johnbokma.com/
# License: The Artistic License
#
# $Id$
use strict;
use warnings;
use XML::Parser;
use File::Find;
@ARGV or die "usage: xmlelements-report DIR [DIR ...]\n";
my %elements;
my @element_stack;
my $parser = XML::Parser->new(
Handlers => {
Start => \&start_element,
Char => \&characters,
End => \&end_element,
},
);
find \&process_xml, @ARGV;
print join( "\t",
qw( Name Occurences Attributes Children Characters )
), "\n";
for my $element ( sort keys %elements ) {
print "$element\t$elements{ $element }{ count }\t",
join (", ", sort keys %{ $elements{ $element }{ attribute } } ),
"\t",
join (", ", sort keys %{ $elements{ $element }{ child } } ),
"\t",
( exists $elements{ $element }{ characters } ? "yes" : "no" ),
"\n";
}
exit;
sub process_xml {
$parser->parsefile( $_ )
if substr( $_, -4 ) eq '.xml' and -f;
}
sub start_element {
my ( $expat, $element, @attrval ) = @_;
$elements{ $element }{ count }++;
while ( my ( $attribute, $value ) = splice @attrval, 0, 2 ) {
$elements{ $element }{ attribute }{ $attribute }++;
}
@element_stack
and $elements{ $element_stack[ -1 ] }{ child }{ $element }++;
push @element_stack, $element;
}
sub characters {
@element_stack
and $elements{ $element_stack[ -1 ] }{ characters } = 1;
}
sub end_element {
pop @element_stack;
}